


Have you ever wondered how Google or Hotmail finds and blocks a single spam email out of billions of emails? Or how companies analyze tweets for customer sentiment? Or how questionable content is identified on a Website? Natural language processing (NLP) does this in real time — and it can be used for a lot more than spam filtering.
When it comes to analyzing a company's spend, the old adage "what gets measured gets managed" is definitely true. However, measuring an enterprise's spend when you have free-text fields, or fields where employees can type in any response they want, can be an insurmountable task. Rarely do two people use the same words and phrases to describe the same thing. Even spelling varies. These variations make measuring how much is being spent on a given category or with a given vendor a very common challenge.
Most companies start by implementing business intelligence tools, which will give you reports, but discerning actionable information from those reports is difficult at best. Without analysis and insight, you can't see at a glance who is buying, what they're buying, from whom, when, or at what price. And the main reason for that is that the data is coming from many different sources, systems, departments, and people — all of whom use varying language to identify any given thing. To address this, companies need to find a solution that can consolidate this disparate data into one place, then standardize it so that every mention of the same thing actually looks the same, and finally classifies it so that each purchase falls into a category that accurately describes it.
This is where natural language processing comes in. NLP enables computers to derive meaning from human or natural language, and it has proved to be a reliable automated solution to these resource-intensive processes. NLP is a branch of artificial intelligence that analyzes, understands, and generates the languages that humans use naturally in order to interface with computers.
If NLP can classify an email as important or spam and a tweet as good or bad, then it can similarly classify spend data into appropriate spend categories. With typical spend data, the fields available to facilitate spend classifications are the supplier's name, general ledger account information, and unstructured free-text information, such as purchase-order description, purchase-order line description, and invoice description. Free-text classification is the biggest challenge, as it is voluminous and does not follow any structure.

Try answering these questions from this raw data:
1. How much am I spending at Walmart?
2. How much am I spending on network hardware?
3. How much am I spending on housekeeping equipment?
To get to each answer, you need to read between the lines and understand that the three supplier entries are actually all the same, despite the different text, and you have to know that the floor scrubber falls under housekeeping, while the routers fall under networking equipment. But with thousands of entries, and humans doing all the classification, it could take weeks to answer these questions. To make matters worse, a typical BI tool can't answer these questions at all.
For any type of machine to discern this level of information across thousands of entries, it needs to first normalize them. NLP is able to "read" the information and discern the correct meaning. It would normalize the three Walmart entries into a single entry of "Walmart," and it would classify the purchase order descriptions into preset commodities as follows:
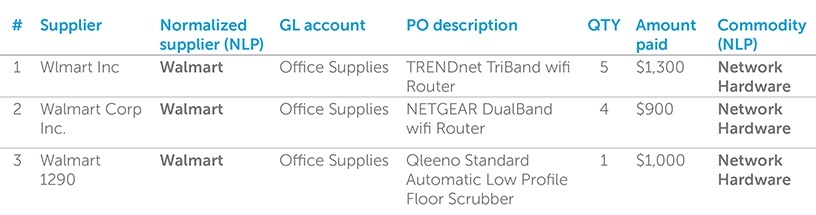
Now the answers to the questions posed are only a few clicks or queries away.
NLP is equipped with various features, which can normalize these instances to Walmart. The process could begin with a few simple operations to remove special characters, such as hyphens, followed by the removal of trailing numbers and extra white spaces. It can remove irrelevant words like "Inc.," "Ltd.," & "Corp." using a stop-word mechanism. Finally, various clustering techniques can find similarities in resulting text and can group them into a single "Walmart." Interestingly, some phonetics-based techniques can detect spelling errors.
The classification with NLP also includes preprocessing of data before it is handed over to the NLP classifiers. The idea behind classification is to teach the classifier with a few pre-classified examples, or a training sample. Feeding a training sample that is representative of the complete dataset gives the best accuracy and significantly reduces effort in classification. Imagine classifying complete data with 100,000 lines vs. only a 5% sample of 5,000 lines. The classifier will extrapolate this 5,000-line sample on your complete dataset and future sets with high accuracy.
For example, if we train the classifier with "TRENDnet TriBand wifi Router" with "Network Hardware" then the classifier will easily classify "NETGEAR DualBand wifi Router" in "Network Hardware," disregarding the manufacturer and band value differences. I.e. Trendnet or Netgear and Triband or Dualband. The classifier will calculate the likelihood of these words to fall under the "Network Hardware" umbrella individually and for when they come together from the training example. This learning is successively applied on the complete dataset. The accuracy of classification will largely depend on the sample selection and sample accuracy. The sample can be tweaked to account for new patterns and will continually improve without losing historical training. This solution is also taxonomy-agnostic and doesn't require additional hardware or changes in infrastructure.
With NLP as part of an enterprise's overall spend analytics solution, companies gain new insight into their spend. They can quickly see how much they're spending with a global vendor, even if purchases were made through different channels, in different locations, and with somewhat different names. Managers can quickly see who is spending the most and spot noncompliance. They can also quickly ascertain what the company is spending money on, and recommend appropriate actions. If, for instance, they see that a large sum of money is going for laptop repairs, a manager may suggest it's more economical to purchase new laptops. This type of expense would be very difficult to see with a traditional BI tool, especially if the company uses local repair vendors around the world to save on shipping costs. But NLP technology can classify repairs as such, providing an enormous amount of visibility to that they've never had before.
While these immediate benefits are key, they are also only the tip of the iceberg. Over time, companies with NLP in place will develop a detailed and authentic supplier database, improving supplier leverage. This can dramatically expedite sourcing initiatives, as the necessary research is now only a few clicks away. Another long-term benefit is that NLP incorporates machine-learning techniques, which means it improves over time. As it works, data will essentially get cleaner every day, leaving a trail of clean data to compare against. This will facilitate complex comparison reports, such as year-on-year spend for a given category or vendor. And last, companies will start to see sizable cost reduction, as NLP identifies and continues to improve its identification of maverick spend.
Well-trained NLP solutions can potentially reduce 40 to 50% of human effort toward data cleaning and enrichment. Solutions based on NLP can potentially be used to enrich and provide granular spend visibility at an enterprise level. Clean and enriched spend visibility can aid organizations in sourcing initiatives with a potential of unearthing 10 to 15% savings. If hiring an external agency for spend classification, it is a good idea to look for such capabilities for faster turnaround, accuracy, and reliable results.
To learn more about spend analytics, check out our latest eBook for free!

Sushil Sharma is a procurement specialist with eight years of experience in deploying spend analysis solutions for Fortune 100 companies. He uses natural language processing (NLP) to design automated data-enrichment solutions. A natural language problem solver and project manager, Sushil finds actionable savings in complex spend analysis problems and rolls out BI capabilities enriched from geographically diverse data across multiple industries. His solutions help CXOs make critical decisions and derive valuable insights on an ongoing basis. Sushil holds a Bachelor of Pharmacy degree from Kurukshetra University and post-graduate diploma in clinical data management from ICRI.
This article was originally published on EBNOnline.com on July 16th, 2015.