Michael Jahrer, VP of applied machine learning at Opera Solutions, proves his data science mettle by using deep learning to predict who will be a safe driver in the year ahead.
Porto Seguro, the third-largest insurance company in Brazil, set out to improve its predictions of who would file an insurance claim in the next year. The company sponsored a competition through Kaggle, the premier platform for predictive modeling and analytics competitions, and our own Michael Jahrer, VP of applied machine learning, took home the win.
Read More
Topics:
Data Science,
Machine Learning,
Analytics,
Artificial Intelligence

Data is the lifeblood of most organizations these days. The insights that come from a company’s data can help drive major — and minor — decisions, providing incremental boosts in company performance on a regular basis and even drastic boosts on occasion. But if you’re not seeing these kinds of results from your data, your problem might not be the analytics. It’s more likely that you’re missing key steps in preparing the data and ensuring its quality.
Proper data preparation ensures the ability to access both internal and external sources of data and transform these data sets into a form that’s ready for analysis. This might involve various forms of data transformation, including processes for improving data quality. Data scientists spend up to 80% of their time preparing data for analysis and ensuring its quality, leaving only 20% to do the actual modeling and analysis that deliver the relevant, actionable insights companies are after.
These numbers are not new, and they shouldn’t be a surprise to anyone reading this. But for those wondering what exactly goes into the process, why it takes up so much of scientists’ time, and why data prep and data quality are so important, we spell it out here.
Read More
Topics:
Big Data,
Data Science,
Data Equity
Many people are under the impression that great marketing is an art, but the field of data science has introduced a scientific component to marketing campaigns. Clever marketers are now relying on data more than ever to assess, test, and plan their strategies. Although data and analytics will never replace the creative minds behind the best marketing campaigns, they can provide marketers with the tools to help improve performance.
Read More
Topics:
Data Science,
predictive analytics
In our new podcast series, The Data-Driven CMO, Opera Solutions Senior Vice President John Kelly interviews Julie Cary, CMO of La Quinta Inns and Suites, who has developed a strong reputation as both a traditional and digital marketer in her dde-long tenure with the company. She discusses the steps taken to integrate Big Data and data science into La Quinta’s everyday marketing operations.
Julie shares how she balanced marketing, technology, data science, and IT and secured the necessary budgets to develop a robust digital marketing environment with tangible marketing results.
Read More
Topics:
Data Science,
Marketing
Shopping around for a Big Data analytics solution is a daunting task for anyone. But for those who are somewhat familiar with data science, a common area of misunderstanding — and underestimating — is clustering techniques. Whether the assumption is that all clustering techniques are created equal or that a company needs only one or two clustering techniques, business buyers are often left scratching their heads. The fact is several types of clustering techniques exist — each with its own strengths and weaknesses — and companies need access to a variety of techniques to accomplish optimal results.
Read More
Topics:
Big Data,
Data Science,
Analytics
What’s the big deal about Millennials? For starters, they’re now the biggest demographic in America. But their needs are unlike any generation before them. Here’s what retailers must know to succeed in marketing to this 80-million–strong population.
Millennials are now the largest living generation in the United States, according to the US Census Bureau. Defined loosely as those born from the early 80s to the early 2000s, Millennials account for roughly 25% of the US population at 83.1 million, exceeding the 75.4 million Baby Boomers in the country. They grew up with household computers, cell phones, and myriad other forms of technology, and they entered the work force during the Great Recession, which has made them price-conscious, tech-savvy shoppers — and robust savers. About half of them still live at home, and they’ve taken over the work force. While most are holding off on marriage, nearly 40% have children and 9% live with domestic partners, indicating that they’re starting families and establishing households (i.e. shopping and spending). Perhaps the most telling stats come from a study from FutureCast, which says that Millennials’ purchases are most influenced by their social circles and that they’re the first generation to influence older generations.
Read More
Topics:
Big Data,
Data Science,
Marketing
In this interview with PYMNTS, Laks Srinivasan discusses the challenges and opportunities the Big Data brings to the world's largest enterprises.
Big Data may be everywhere, but that doesn’t mean that companies are able to actually get the most out of it in an efficient and scalable way.
With the notion that the world’s flow of computable information would eventually become the oil of the twenty-first century, Opera Solutions was launched back in 2004 with the goal of addressing the challenges and opportunities emerging as a result of the influx of data that came from more people having increased access to technology and a greater ability to generate even more data.
Read More
Topics:
Big Data,
Data Science,
Machine Learning
Artificial Intelligence (AI) is helping the enterprise create dynamic new applications and new ways to better serve customers, prevent and cure diseases, detect security threats, and more. We’re seeing how rapid advances in the field as a whole as well as the underlying technology are leading to more real-world opportunities that already are making a big impact. Speaking at a 2017 panel discussion with the The Wall Street Journal, AI luminary Andrew Ng observed, “Things may change in the future, but one rule of thumb today is that almost anything that a typical person can do with less than one second of mental thought we can either now or in the very near future automate with AI.” That’s a startling assessment for what we can expect.
Read More
Topics:
Big Data,
Data Science,
Machine Learning,
Artificial Intelligence
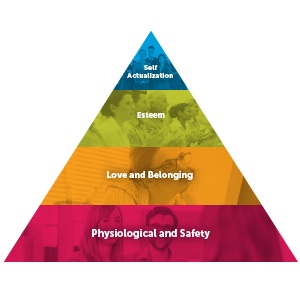
In my role of leading Product Management and Presales at Opera Solutions, I am constantly exposed to direct customer interactions, most often in the early stages of the sales cycle. In these meetings, part of my job is to assess our prospective customer’s pain points and needs as much as they are assessing our products, technology, and capabilities. Thus, given the exposure we get at Opera Solutions, I am in a good position to understand real-world business needs around analytics across industries.
We often talk about corporate cultures, but the experience with hundreds of customers led me to think of corporate psychology, and juxtaposing Maslow’s hierarchy of needs to the current state of data science adoption and readiness in the industry. Companies need to recognize the stage they are in and not be seduced by the hype or promise of the technology. Data science adoption needs not follow a sequential maturity process; dynamic corporations can certainly accelerate things when the need and will exist. So for fun, here’s a take on Maslow’s Hierarchy of Needs adapted to data science.
Read More
Topics:
Big Data,
Data Science
To predict the future, one must look at the past, says the old adage. To determine what to expect in 2017, we thought it was best to draw lessons from 2016 despite our industry’s yearning for dramatic change. Laks Srinivasan, COO at Opera Solutions, shares his insights into the biggest Big Data trends of 2016 and reflects on where the market is going and how companies will react.
Read More
Topics:
Big Data,
Data Science,
Machine Learning,
Artificial Intelligence